
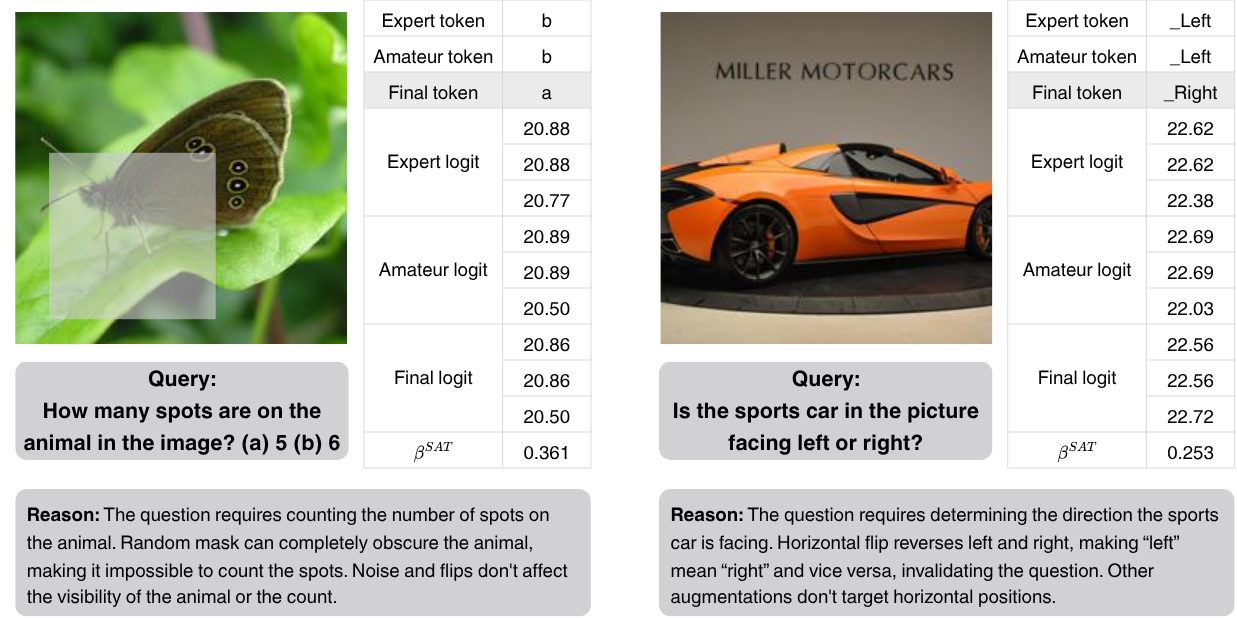
Self-Aug examples on MMVP.

Self-Aug examples on MME.
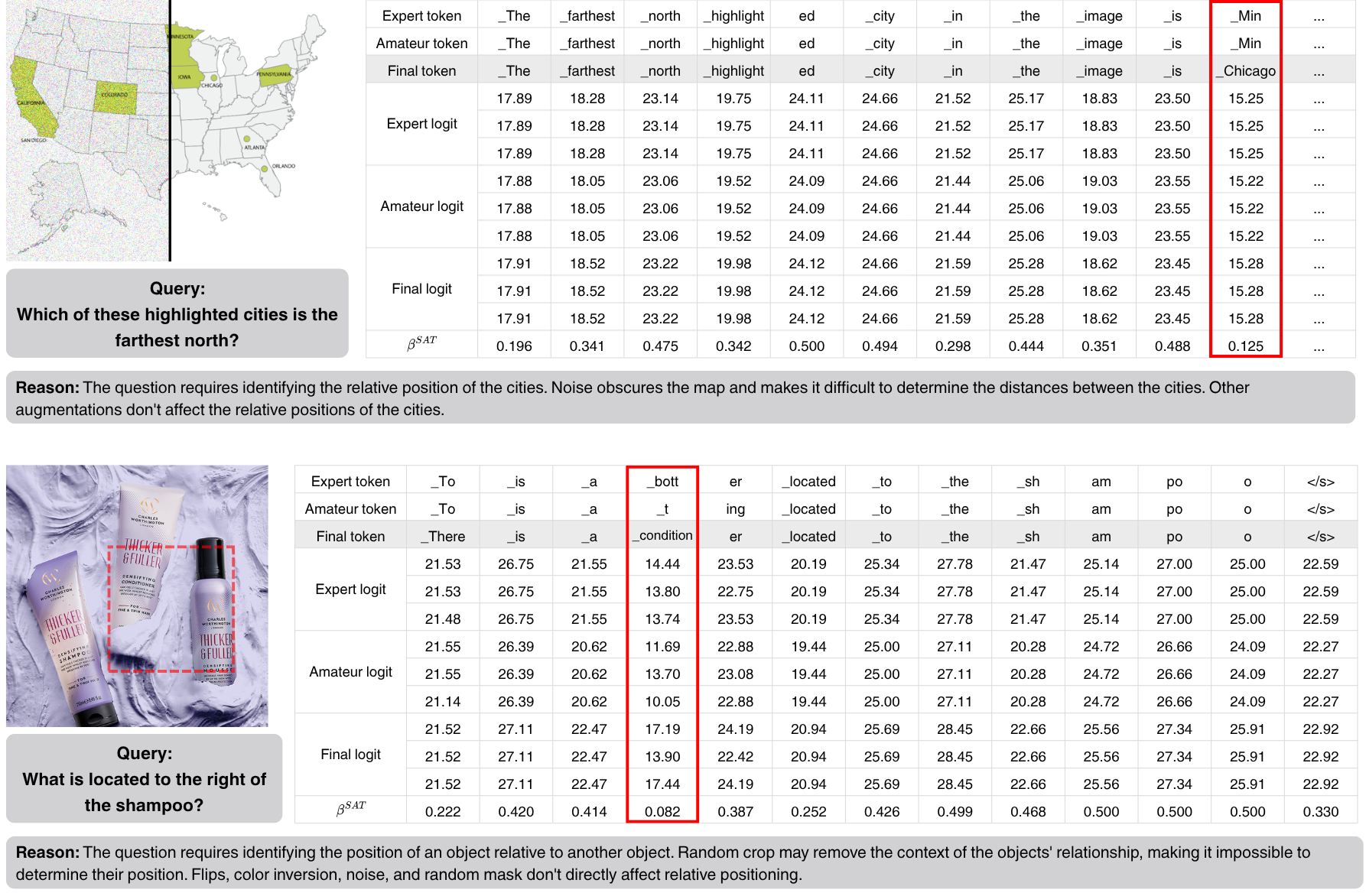
Self-Aug examples on MM-Vet.
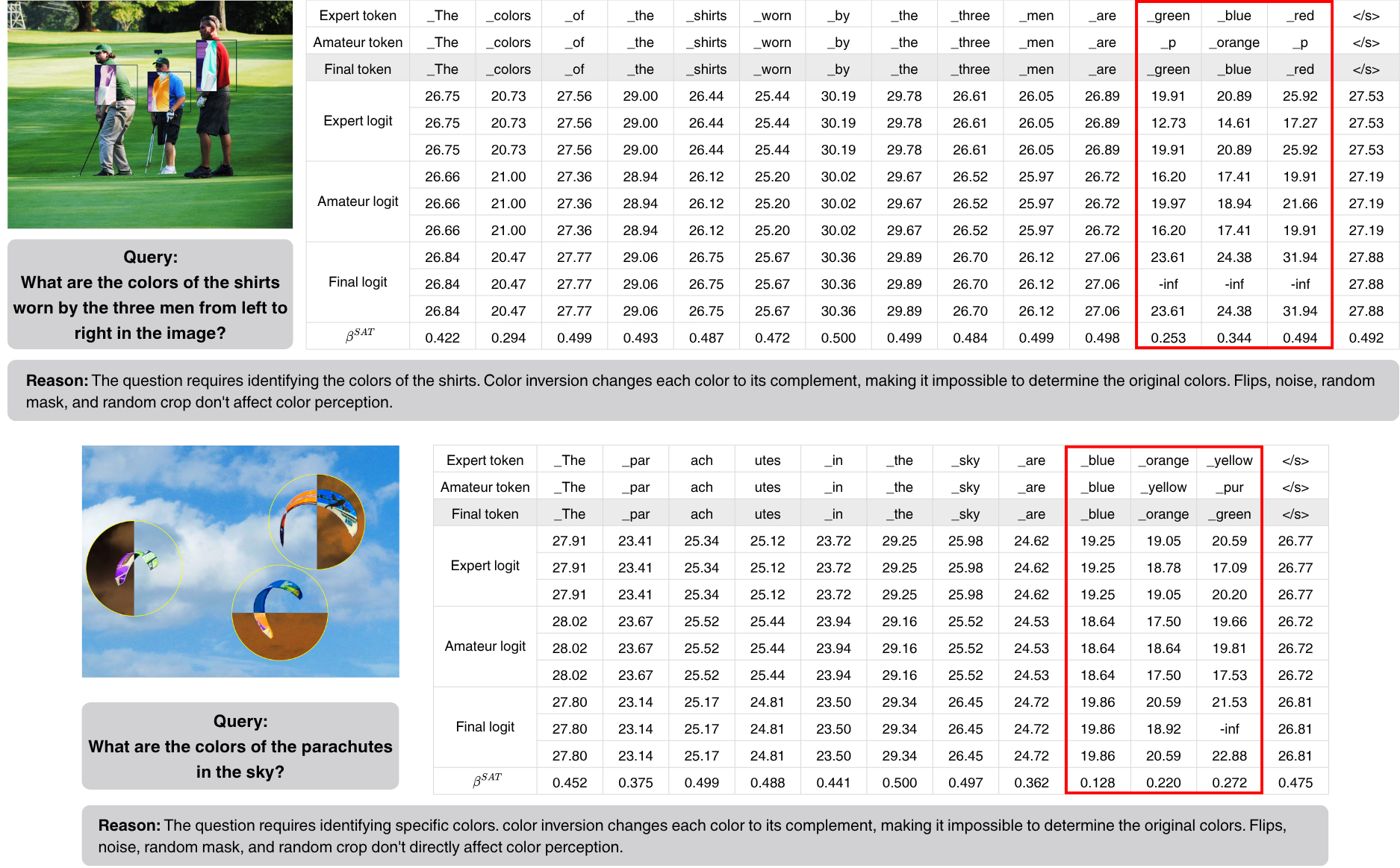
Self-Aug examples on MMHal-Bench.
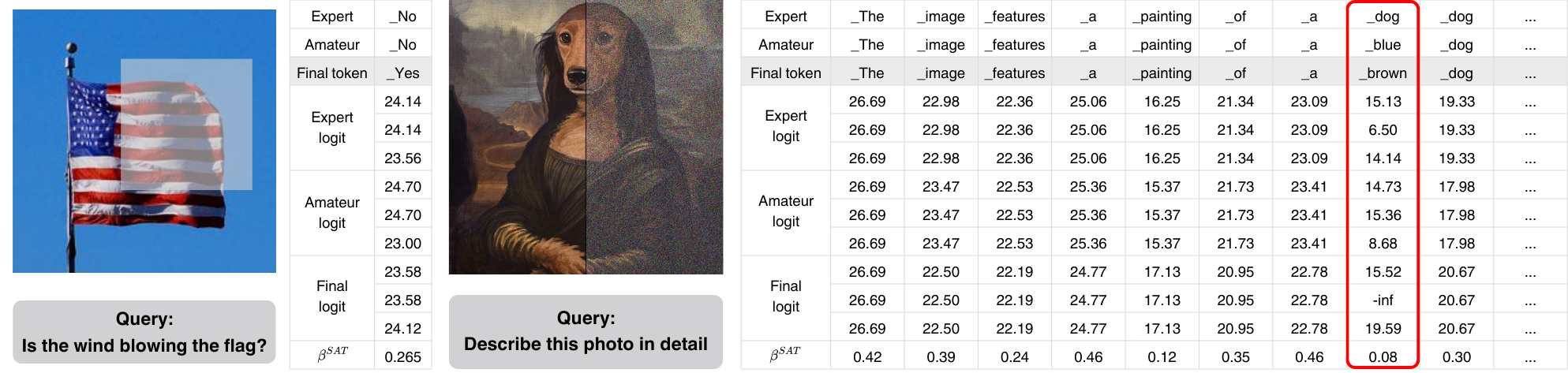
Token-level analysis.
Large Vision-Language Models (LVLMs) have demonstrated remarkable multimodal capabilities, but they inherit the tendency to hallucinate from their underlying language models. While visual contrastive decoding has been proposed to mitigate this issue, existing methods often apply generic visual augmentations that disregard the specific context provided by the text query, limiting their effectiveness. This study introduces a novel training-free decoding strategy that addresses these limitations, featuring two key contributions. First, a self-augmentation prompting strategy that leverages the intrinsic knowledge of the model to dynamically align semantics between the query and the visual augmentation. Second, an adaptive thresholding algorithm that adjusts next-token candidate size based on output sparsity, utilizing full information from the logit distribution. Extensive experiments across four LVLMs and seven benchmarks demonstrate that the proposed decoding significantly enhances factual consistency compared to state-of-the-art decoding methods. This work highlights the importance of integrating query-dependent augmentation and entropy-aware decoding for improving effective generation of LVLMs.
To address the research questions, we present Self-Aug, a confidence-aware decoding method that achieves semantic alignment between the query and visual augmentation. The proposed method integrates seamlessly into any LVLM without requiring architectural modifications or additional training. Self-Aug is composed of the following two components.
Self-Augmentation Selection (SAS): SAS aims to employ parametric knowledge of the LVLM to dynamically select a task-optimal visual augmentation on the fly that amplifies output divergence. The SAS prompt involves: (1) explicit definitions of each visual augmentation and their corresponding effects for injecting operational knowledge, (2) structured reasoning instructions to minimize the risk of post hoc rationalization, and (3) in-context examples for providing contextual knowledge.
Sparsity-Adaptive Truncation (SAT): SAT mitigates false-positive generation by leveraging the principle that sparsity is inversely related to uncertainty. A lenient threshold is required in high-entropy scenarios, while a restrictive threshold is favored in low-entropy cases. We set βSAT with a decayed entropy function based on Shannon entropy and a sigmoid. Since a value in the logits is relative to the others, the inverse-entropic principle ensures confidence awareness.

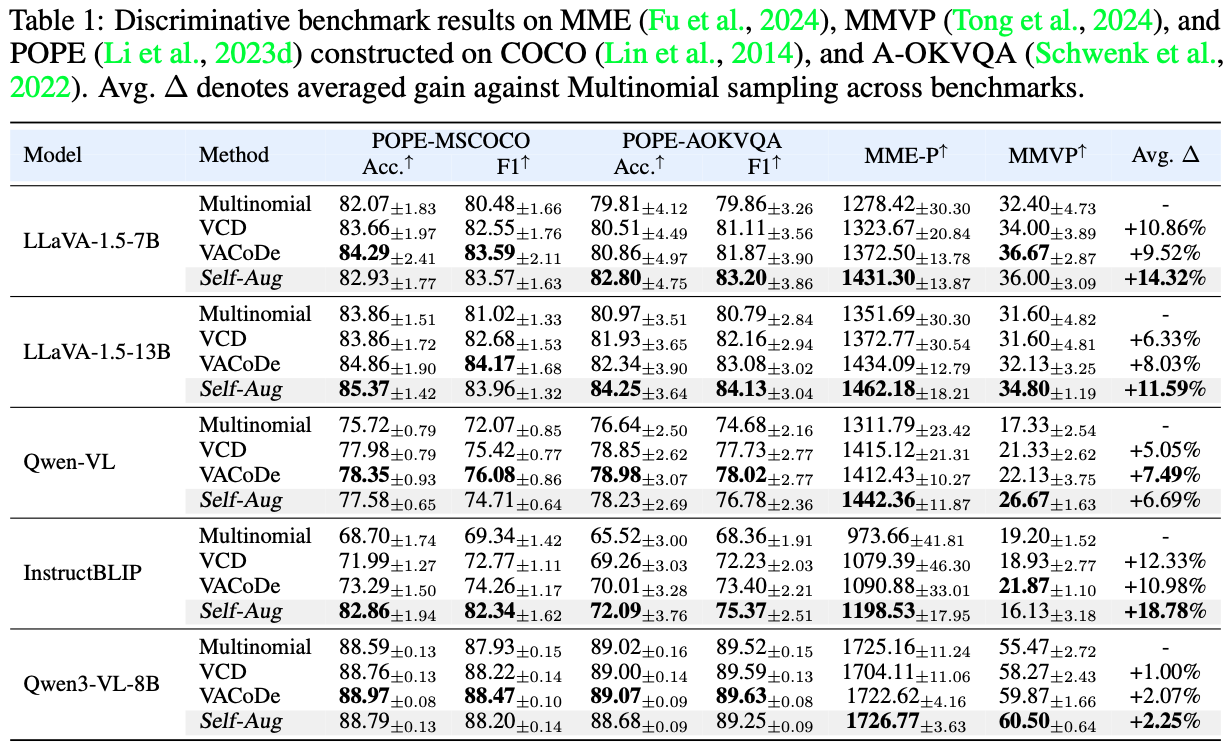
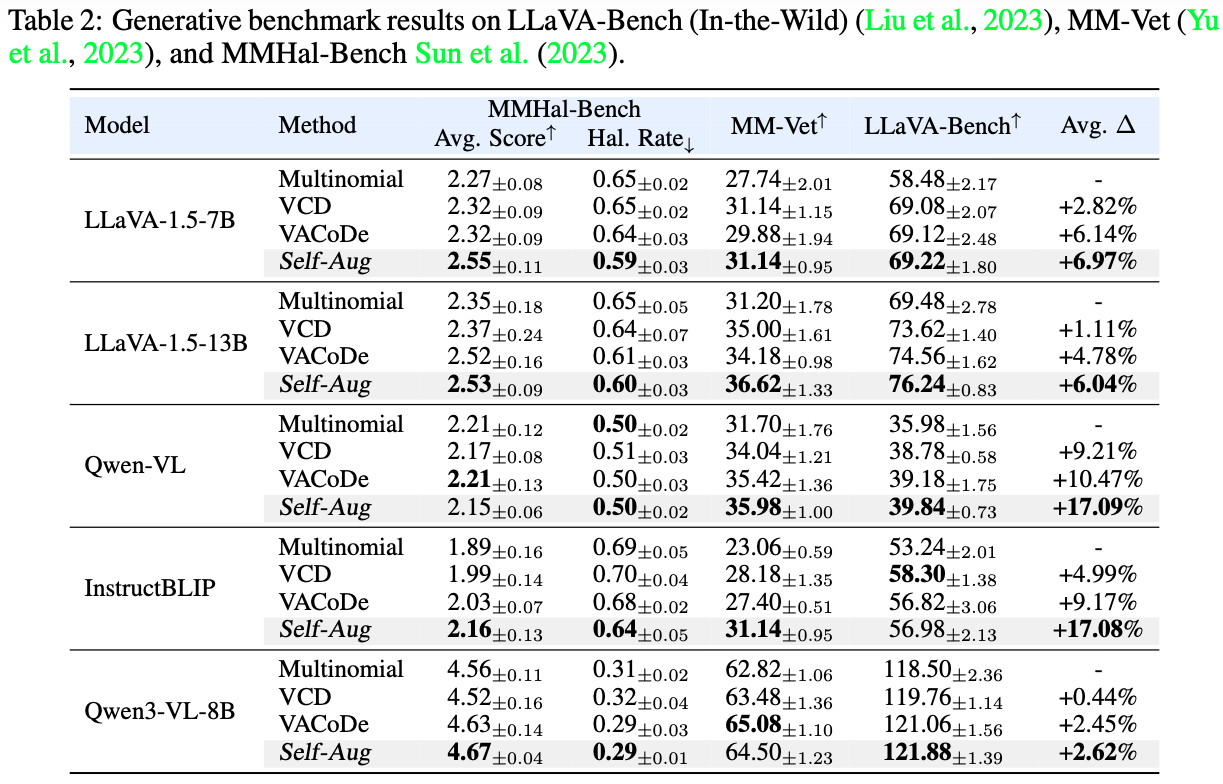
Discriminative benchmarks assess the factuality of visual recognition in the form of binary or multiple-choice questions, while generative benchmarks evaluate broader capabilities by requiring open-ended responses. Self-Aug achieves remarkable performance gains across both benchmark categories, ranging from 6.69% to 18.78% relative to multinomial sampling.
How does Self-Aug actually work? This token-level study demonstrates the mechanism through three key observations. (1) The example on the left shows a case of failure correction, where the contrastive process between two logits successfully elevates the score for the correct Yes token, making it the final answer. (2) The example on the right shows a hallucination penalty, where random noise triggered hallucination of the blue token from the amateur logit. It is penalized through subtraction, causing its final score to fall below the SAT threshold and be removed from the candidate set. (3) The adaptive nature of the SAT threshold (βSAT) is observed, with a higher threshold applied to common tokens (for example, articles and prepositions) and a lower threshold applied to informative, lower-confidence tokens (for example, painting, the red-boxed token). These findings validate both core components of Self-Aug, confirming that contextually relevant augmentation selection with model knowledge can effectively amplify output divergence by invalidating the premise of the question, while confidence-aware SAT further improves token selection.
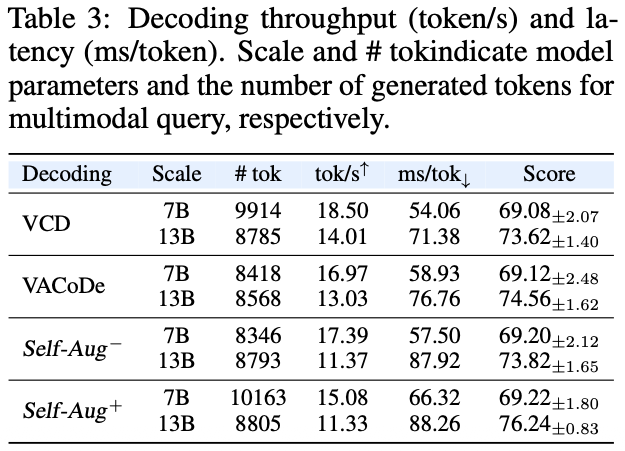
We compare the computational complexity of Self-Aug against the query-static method (VCD) and another query-specific method (VACoDe). Superscripts + and - denote strong prompting and efficient prompting, respectively. While VACoDe searches for the optimal augmentation in a brute-force manner, Self-Aug demonstrates an architectural advantage by requesting a single text-only generation pass, bypassing the main computational expense of visual tokens, which constitute the majority of the input. This architectural feature enables a flexible trade-off between performance and latency. While full prompting incurs a cost comparable to VACoDe, the cost-optimized prompting exhibits substantially higher efficiency.
Self-Aug examples on MMVP.
Self-Aug examples on MME.
Self-Aug examples on MM-Vet.
Self-Aug examples on MMHal-Bench.
Token-level analysis.
@inproceedings{imself,
title={Self-Aug: Query and Entropy Adaptive Decoding for Large Vision-Language Models},
author={Im, Eun Woo and Ali, Muhammad Kashif and Gupta, Vivek},
booktitle={The Fourteenth International Conference on Learning Representations}
}