
Figure 1. Lexical concreteness matter more: perturbing abstract
keywords yields only minor visual changes,
while perturbing concrete keywords creates larger structural changes
and stronger hard negatives.
Contrastively pretrained multimodal representation models often behave like bag-of-words, limiting compositional understanding. Hard negatives (mismatched sample but shares significant semantics with the original pair) can help, but not all generated negatives are equally informative (Figure 1). Among multiple hard negative transformations, we ask which caption concepts create the most effective hard negatives and how to maximize their utility.
To address the research questions, we present Concrete Jungle, a concreteness-paved training framework that improves compositional understanding through stronger hard negative mining and better optimization. The proposed method integrates seamlessly into contrastive vision-language pretraining and tackles the problem from both the data and objective sides. Concrete Jungle is composed of the following two components.
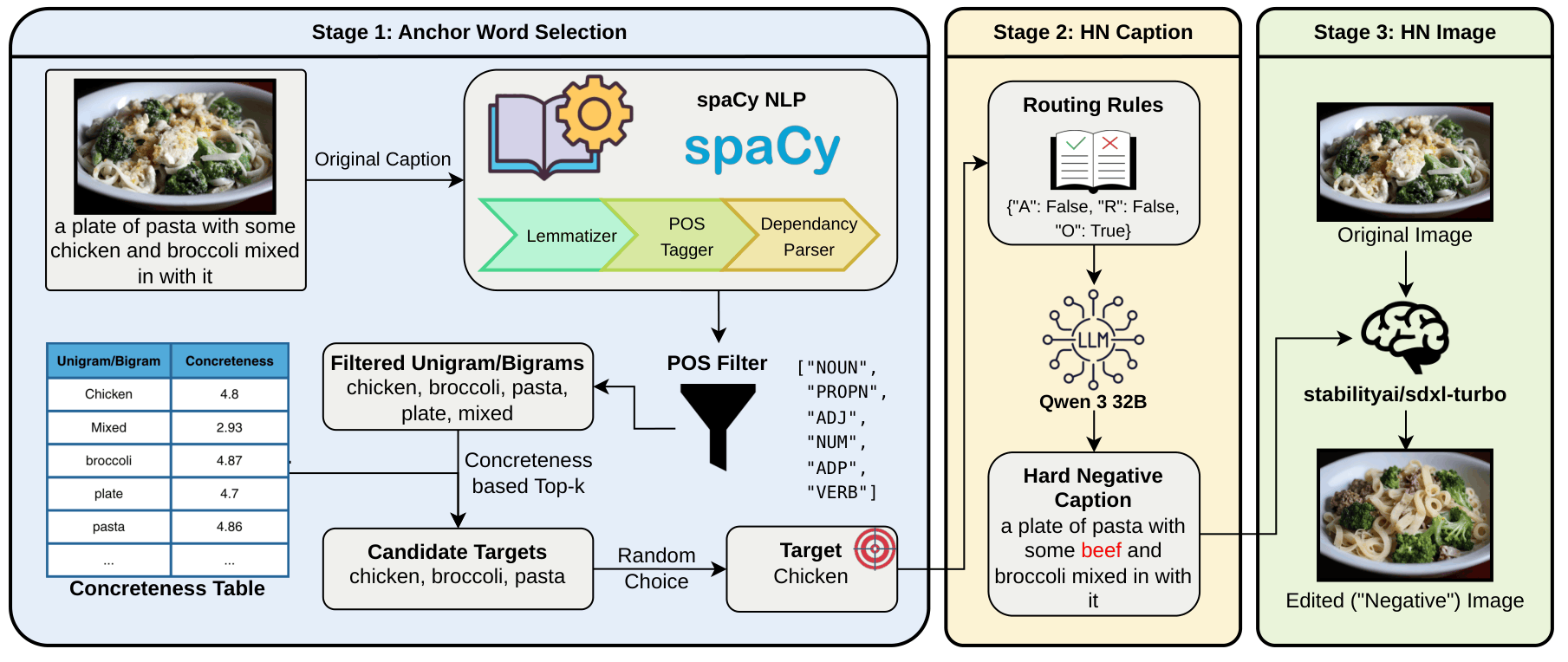
ConcretePlant: ConcretePlant aims to generate more effective hard negatives by perturbing caption concepts in the given caption that are most likely to induce meaningful visual and structural changes. Instead of treating all words equally, it prioritizes concrete concepts, which tend to correspond to perceptually grounded entities and attributes. By leveraging lexical concreteness, ConcretePlant controls the perturbation process toward harder and more informative negatives for compositional learning.
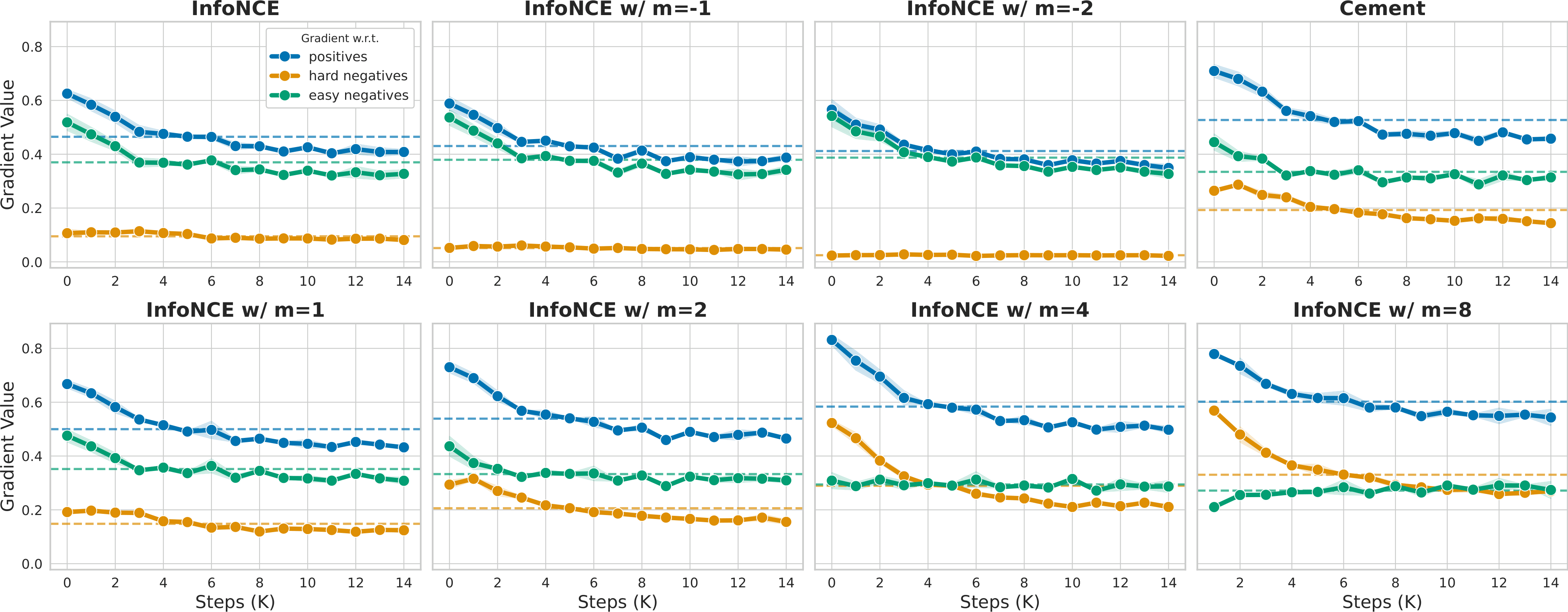
Cement Loss: Cement Loss addresses the optimization challenge that emerges when hard negatives are added to the training batch. We identify a gradient imbalance in standard contrastive learning, where easier pairs dominate the optimization signal and reduce the contribution of informative hard negatives. This issue becomes more severe when hard negatives are introduced, as they effectively enlarge the batch and increase the number of competing negatives. However, simply reducing the batch size is not a sufficient solution (Figure 2). Cement Loss mitigates this issue through an adaptive margin that controls gradient magnitudes, thereby rebalancing the optimization process without sacrificing the contrastive signal provided by large batches.
\[ \begin{aligned} L_{\text{Cement}} = -\frac{1}{2N} \sum_{i=1}^{2N} \left( \log \frac{\exp(s_{i,i})}{Z_i^{v \to t}} + \log \frac{\exp(s_{i,i})}{Z_i^{t \to v}} \right), \\ \text{s.t.} \quad Z_i^{v \to t} = \exp(s_{i,i}) + \exp(s_{i,i'} + \hat{m}_i) + \sum_{j \notin \{i,i'\}}^{2N} \exp(s_{i,j}). \end{aligned} \]
\(s_{i,j}\) denotes the similarity between the \(i\)-th image and the \(j\)-th text, \(i'\) denotes the paired hard negative, \(Z_i^{v \to t}\) and \(Z_i^{t \to v}\) are the image-to-text and text-to-image normalization terms, and \(\hat{m}_i\) is the adaptive margin that regulates gradient magnitudes. In the figure above, \(m\) refers to a static margin baseline, while Cement Loss uses the adaptive margin \(\hat{m}_i\).
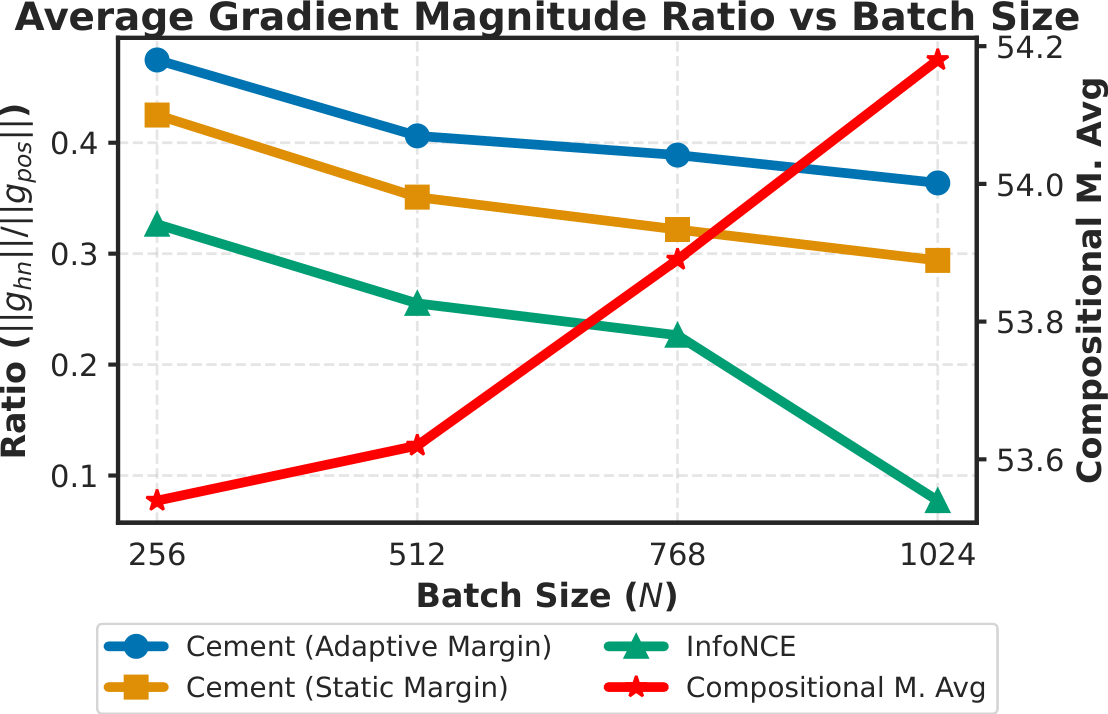
Figure 2. Simple batch size reduction may partially alleviate the imbalance, it also removes negative samples that are necessary for discriminating positive pairs.
Our experiments point to three consistent takeaways.
We first analyze the generated hard negative datasets to verify that concreteness is a meaningful and controllable data-quality factor. We compare three sampling regimes: high-concreteness, low-concreteness, and unconstrained sampling. These analyses validate the following core hypothesis and findings.
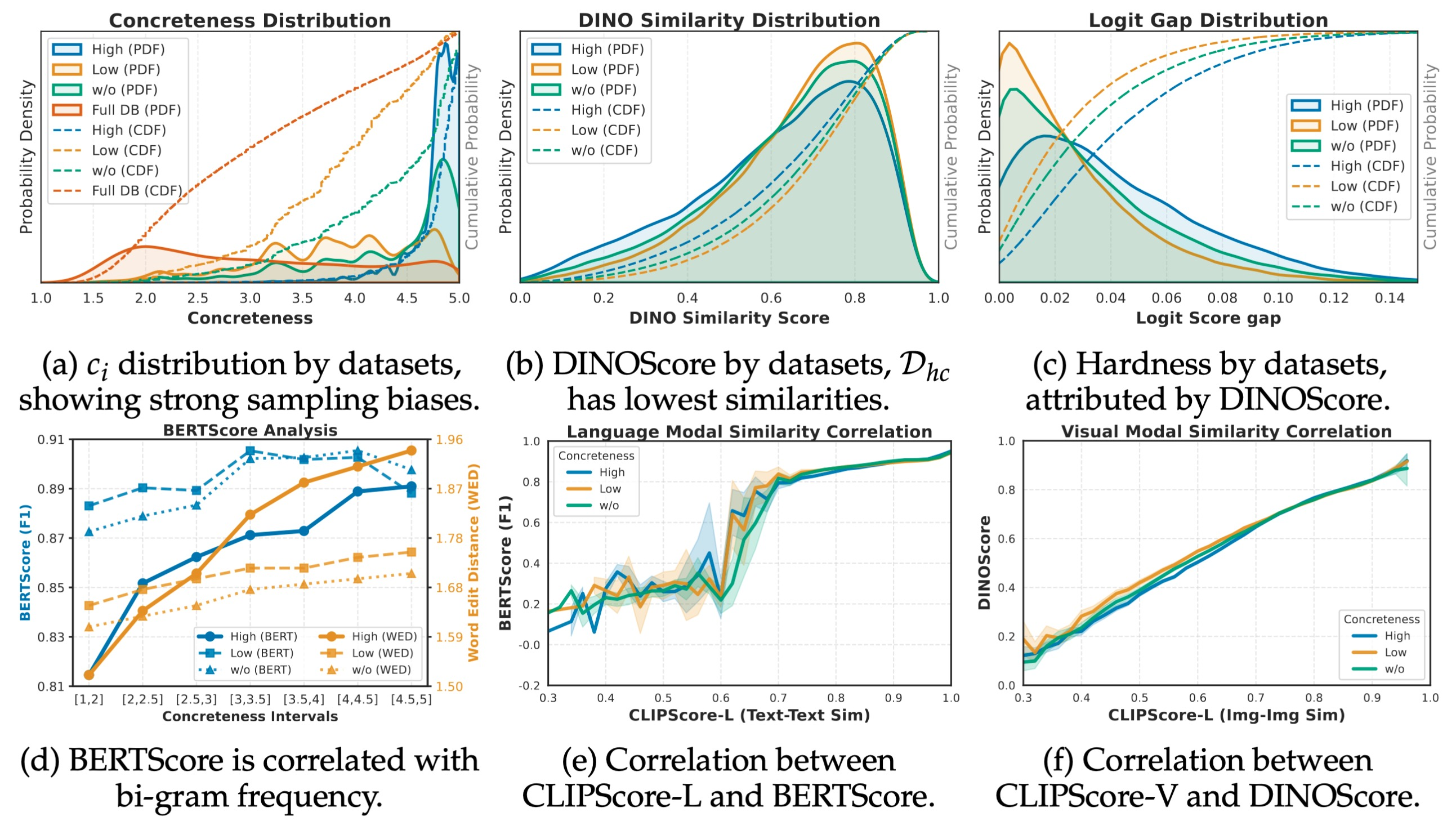
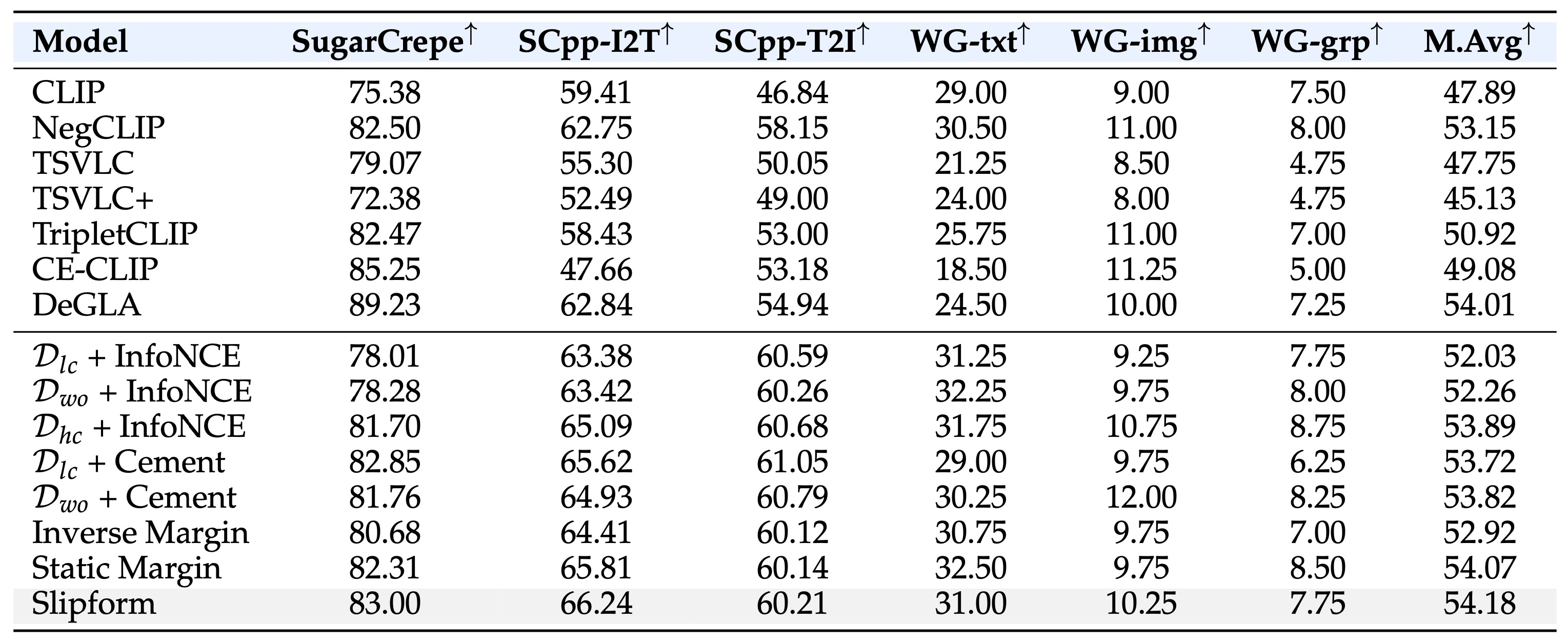
Table 1. Compositional understanding benchmark. Performance is evaluated with multimodal hard negative retrieval on SugarCrepe, SugarCrepe++, and Winoground. The model must distinguish matched image-text pairs from carefully constructed confounders involving nouns, attributes, relations, and object composition. M.Avg. denotes macro average.
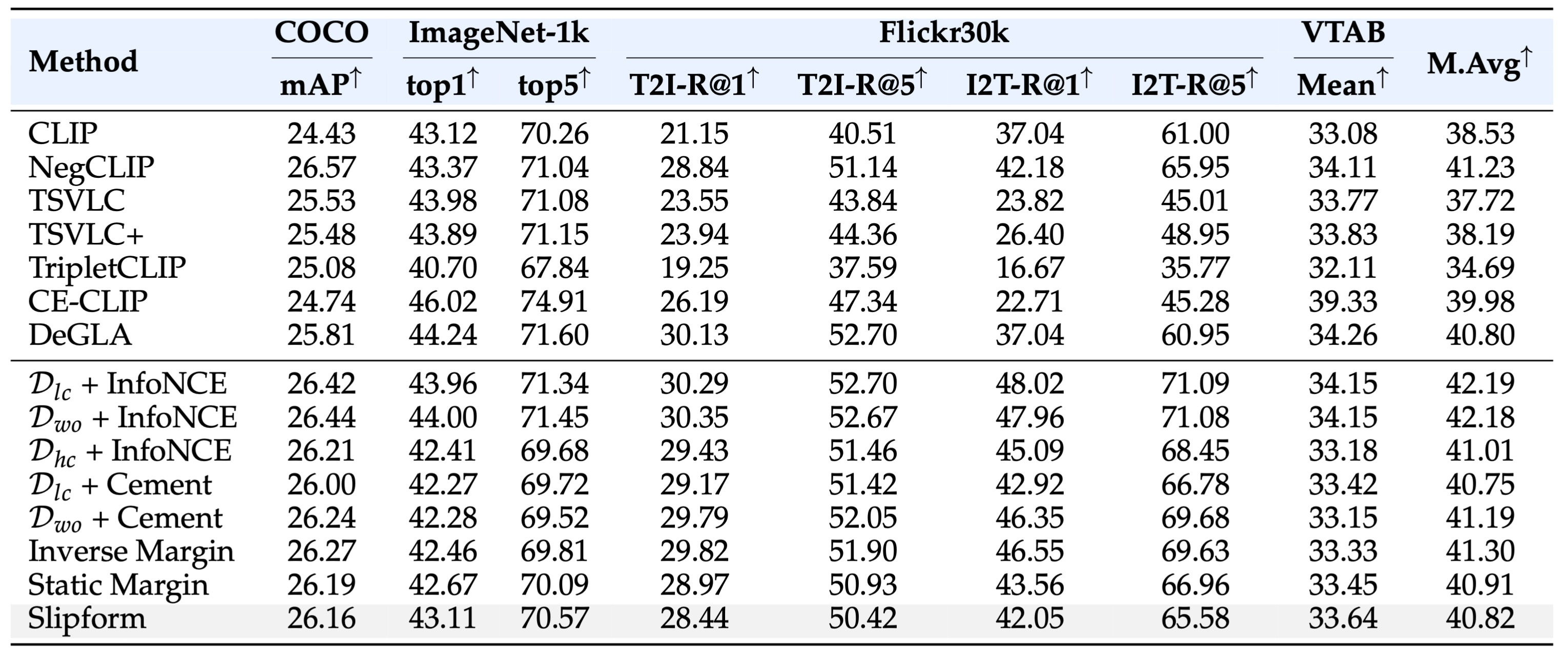
Table 2. General visual representation benchmark. Performance is evaluated with single-label linear probing on ImageNet-1k, multi-label linear probing on MS-COCO, zero-shot retrieval on Flickr30k, and frozen-feature evaluation on VTAB.

@article{im2026concrete,
title={Concrete Jungle: Towards Concreteness Paved Contrastive Negative Mining for Compositional Understanding},
author={Im, Eun Woo and Madhwal, Dhruv and Gupta, Vivek},
journal={arXiv preprint arXiv:2604.13313},
year={2026}
}